Responses to facebook post - "how many in the jar?"
Modified: 2016-12-16
Status: finished
An idle moment on facebook1. Publicity for a small business pops up - their social media person has put up a lolly jar and invited responses to the classic challenge - how many are in the jar? It had garnered quite a few responses - the business was unlikely to be able to follow through on their promise - free stuff if you get it right2.
Plug and chug
1) Plug
Laziness dictates the method.
Naturally that means using the first google hit for “expand facebook comments”. This worked well enough for my purposes. This worked well enough, though it only managed to fetch the last 3,000 comments before hanging, but that seems like enough3.
C&P the expanded comment block into a text file, “raw-data” and have a peek4:
Name mcnameface
Name mcnameface 63
Like · Reply · 35 mins
Also Aperson
Also Aperson 62
Like · Reply · 35 mins
Parents Spawn
Parents Spawn 86
Like · Reply · 35 mins
Has atitle
Has atitle 100
Like · Reply · 35 mins
A Character
A Character 20
and so on for 9,000 lines.
2) Chug
Let’s start with grep to clear out some of the muck. There are a bunch of lines with the time a comment was made such as “35 mins” or “1 hr” which I’ll pick up if I do a naive search for any numerals on a line.
grep -v -E "min|hr" raw-data
The above searches for the string “min” or “hr”, and matches lines that contain either of those strings (and will also match “mins” and “hrs”).
-v will invert the match, so we now match lines which don’t contain the strings “min” or “hr”
-E specifies we are using extended regular expressions, not really needed here. I could just have easily omitted the -E and searched for grep -v "min\|hr" raw-data instead.
All together this will spit out the lines that do not contain “min” or “hr”:
Name mcnameface
Name mcnameface 63
Also Aperson
Also Aperson 62
Parents Spawn
Parents Spawn 86
Has atitle
Has atitle 100
A Character
A Character 20
We can then plumb this output back into grep again to capture those numbers. Naturally we will use pipe, | for said plumbing. Now is a good time to save the output to file also.
grep -v -E "min|hr" raw-data | grep -E -o "[0-9]{1,}$" > filtered-data
[0-9] says “search for any the characters 0,1,2,3,4,5,6,7,8,9.”
{1,} says “look for the preceding expression 1 or more times”
$ says “match the end of the line”
Together these make: “Search for any of the characters 0-9 occurring 1 or more times together at the end of the line” -> Find-us the numb-as.
Using the argument -o will return only the matched string (the string just happens to be a number), not the entire line.
Now we have the much nicer looking:
63
62
86
100
20
In the vast majority of cases this simple filter will capture legitimate guesses.
Determine how many of each guess there was
sort -n filtered-data > sorted-data
cat sorted-data | uniq -c > unique-data
cat sorted-data | uniq > guesses
cat unique-data | grep -E " {2,}[0-9]{1,}" -o | grep -E "[0-9]{,}" > frequency
Now a way to make this nicer ….
I’ve never use gnuplot before, but the ‘gnu’ in the name assures me it is a good choice5.
gnuplot
gnuplot> plot "<paste guesses frequency "
Up until this point, this was all very quick to kludge together. Here, I came unstuck, as I was faced with learning a bit more than I wanted to about a package I didn’t expect to use. So, I shifted to Python and matplotlib for the last little bit.
3) Glug
The low-hanging fruits of our labour:
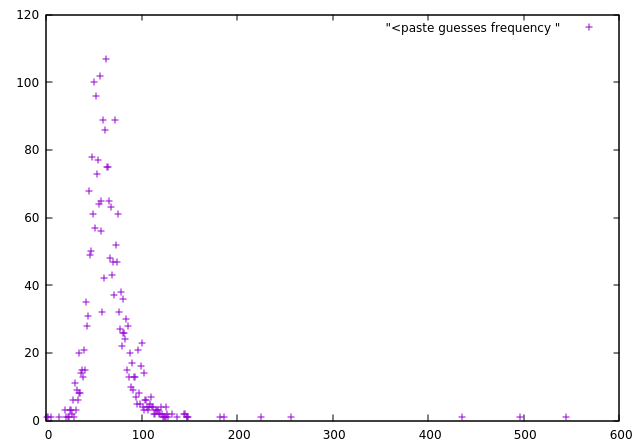
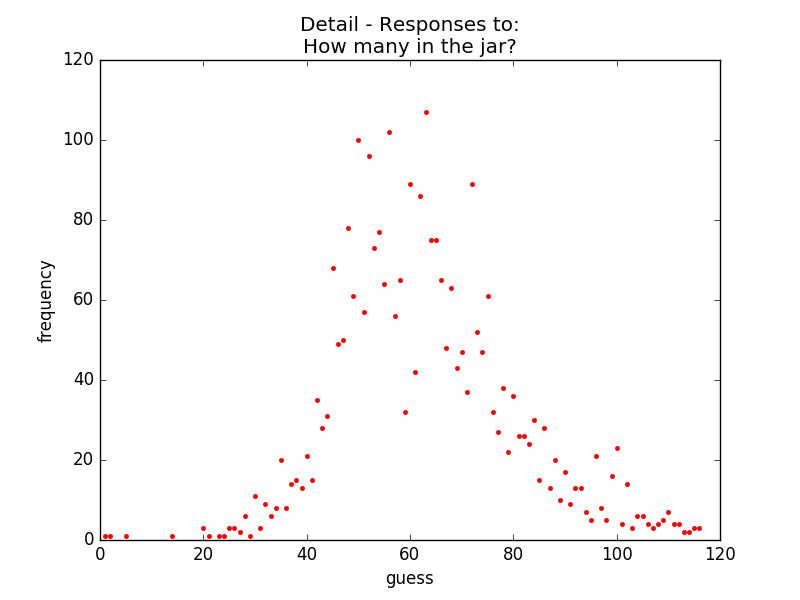
| Mean | Median |
|---|---|
| 64.4 | 62 |
If we trust people in aggregate then:
numberInJar ⊂ {40, ..., 80}
Each number in this range had about 60 guesses in the sample of 3000, about = 2% of the responses. For the >60K comments/guesses made this gives >1200 ‘winners’. Probably more than the couple they were expecting.
Oh, and my own guess? 49. I made sure to make one before I looked at any other replies.
4) Bug (nag)
There is a certain draw to operating on data that was not provided by people knowingly participating in a study. You know the data is free from any ‘self-conscious’ effects that might appear.
Woah, that deserves inspection. Coming from a service provider that would probably sound creepy - “We like it when they give us information and don’t realise it”.
Maybe this is slightly dubious, but all I have done with this data is very benign. I nuked the original capture, so all that’s left is this list of numbers. (Yay, does your information is only stored in anonymised aggregate sound familiar?).
Post has since been removed, I can confidently guess they were overcome by the response.↩
At the time of getting the comments this represented about the most recent 4.5% of all comments made. This means that there is no chance to look at the evolution of guesses over time - I was hoping that maybe this would be a nice example of a trend towards the mean.↩
Names blatantly clobbered.↩
How much is that brand worth anyway? (Note: I couldn’t actually get this to work within the “I’m-vaguely-interested-if-it’s-easy” period. Which was about 5 minutes in this particular case.)↩